随着BIG DATA大数据概念逐渐升温,如何搭建一个能够采集海量数据的架构体系摆在大家眼前。如何能够做到所见即所得的无阻拦式采集、如何快速把不规则页面结构化并存储、如何满足越来越多的数据采集还要在有限时间内采集。这篇文章结合我们自身项目经验谈一下。
爬虫框架
整个框架应该包含以下部分:资源管理、反监控管理、抓取管理、监控管理。
看一下整个框架的架构图:
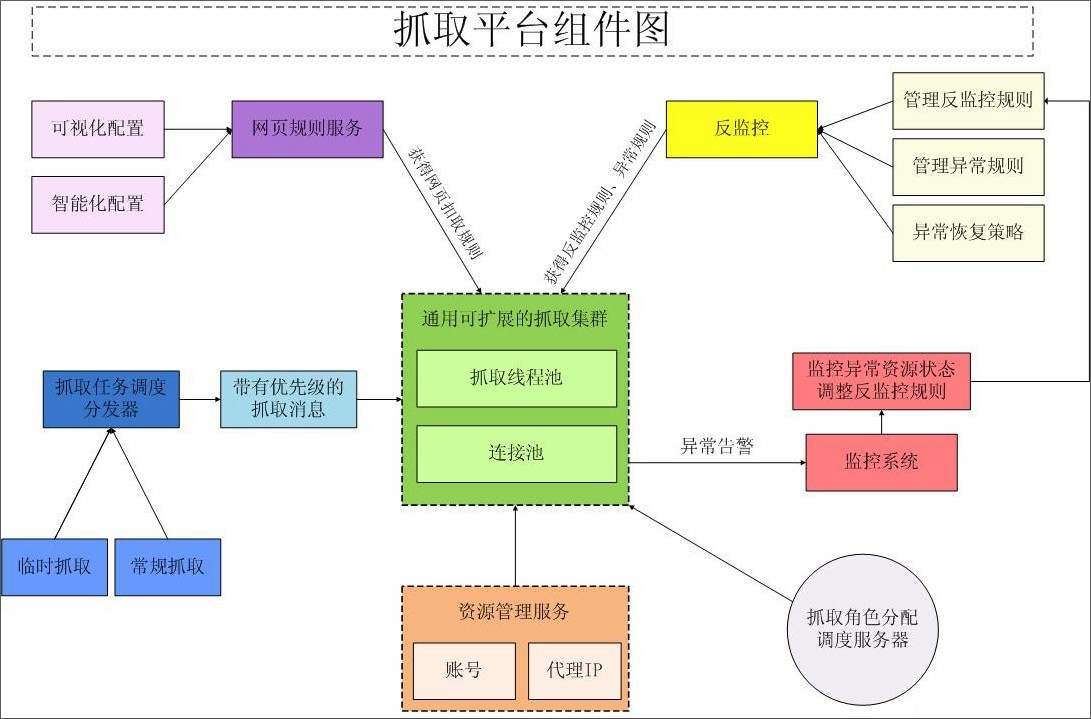
- 资源管理指网站分类体系、网站、网站访问url等基本资源的管理维护;
- 反监控管理指被访问网站(特别是社会化媒体)会禁止爬虫访问,怎么让他们不能监控到我们的访问时爬虫软件,这就是反监控机制了; (more…)
今天无意中蹦出来一个问题,这硬盘的最大容量单位是多少呢?
查了一下,硬盘容量单位换算
1B [Byte] = 8bits字节
1KB [Kilobyte] =1024B
1MB [Megabyte] =1024KB
1GB [Gigabyte] =1024MB
1TB [Terabyte] =1024GB
1PB [Petabyte] =1024TB
1EB [Exabyte] =1024PB
1ZB [Zettabyte] =1024EB
1YB [Yottabyte] =1024ZB
想想要是给我一块1YB的硬盘我该拿它放些什么呢?
就算我每秒钟都在往里面存储数据,我估计这一辈子也存储不满
现在假设我能活到100岁还剩80年
80年*365天*24时*60分*60秒=2,522,880,000秒
1YB硬盘=1,125,899,906,842,627GB
也就是说我每秒要往硬盘里面写入446,275GB的数据,还是在不间断的情况下,
我才能刚好在100岁挂掉的那天把这块1YB的硬盘填满。
这1YB是不是就是传说中的人脑容量?